Abstract
In this work, we address dynamic view synthesis from monocular videos as an inverse problem in a training-free setting. By redesigning the noise initialization phase of a pre-trained video diffusion model, we enable high-fidelity dynamic view synthesis without any weight updates or auxiliary modules. We begin by identifying a fundamental obstacle to deterministic inversion arising from zero-terminal signal-to-noise ratio (SNR) schedules and resolve it by introducing a novel noise representation, termed K-order Recursive Noise Representation. We derive a closed form expression for this representation, enabling precise and efficient alignment between the VAE-encoded and the DDIM inverted latents. To synthesize newly visible regions resulting from camera motion, we introduce Stochastic Latent Modulation, which performs visibility aware sampling over the latent space to complete occluded regions. Comprehensive experiments demonstrate that dynamic view synthesis can be effectively performed through structured latent manipulation in the noise initialization phase.
Method
Our approach leverages the inherent capabilities of pre-trained video diffusion models to achieve dynamic view synthesis through strategic noise manipulation during the initialization phase.
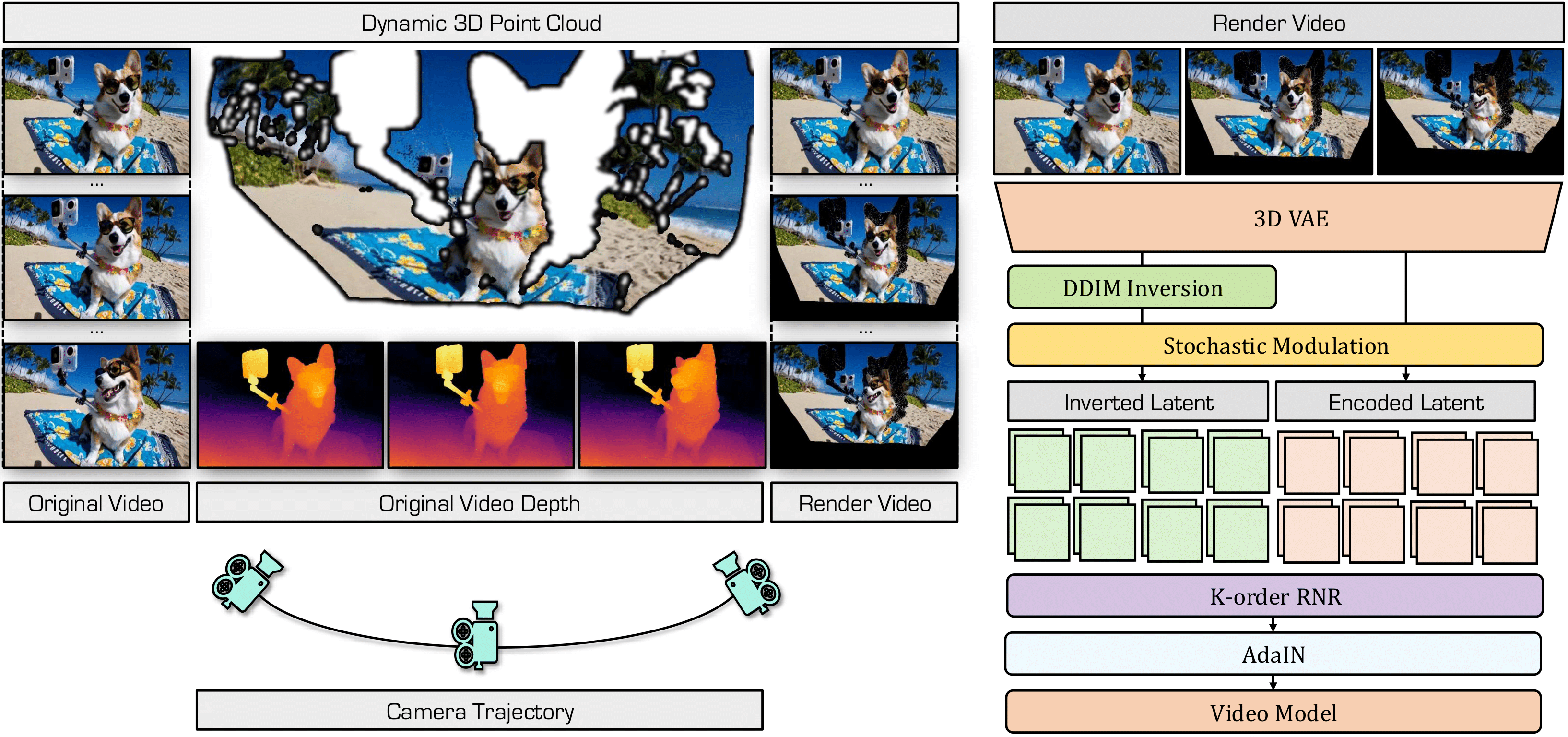
Overview of Our Method. (Left) We lift a monocular video into a dynamic 3D point cloud and render novel views under target camera trajectories, revealing unseen regions. (Right) Our method synthesizes coherent outputs by initializing noise with Adaptive K-order Recursive Noise Representation combined with Stochastic Latent Modulation, without modifying the video model.
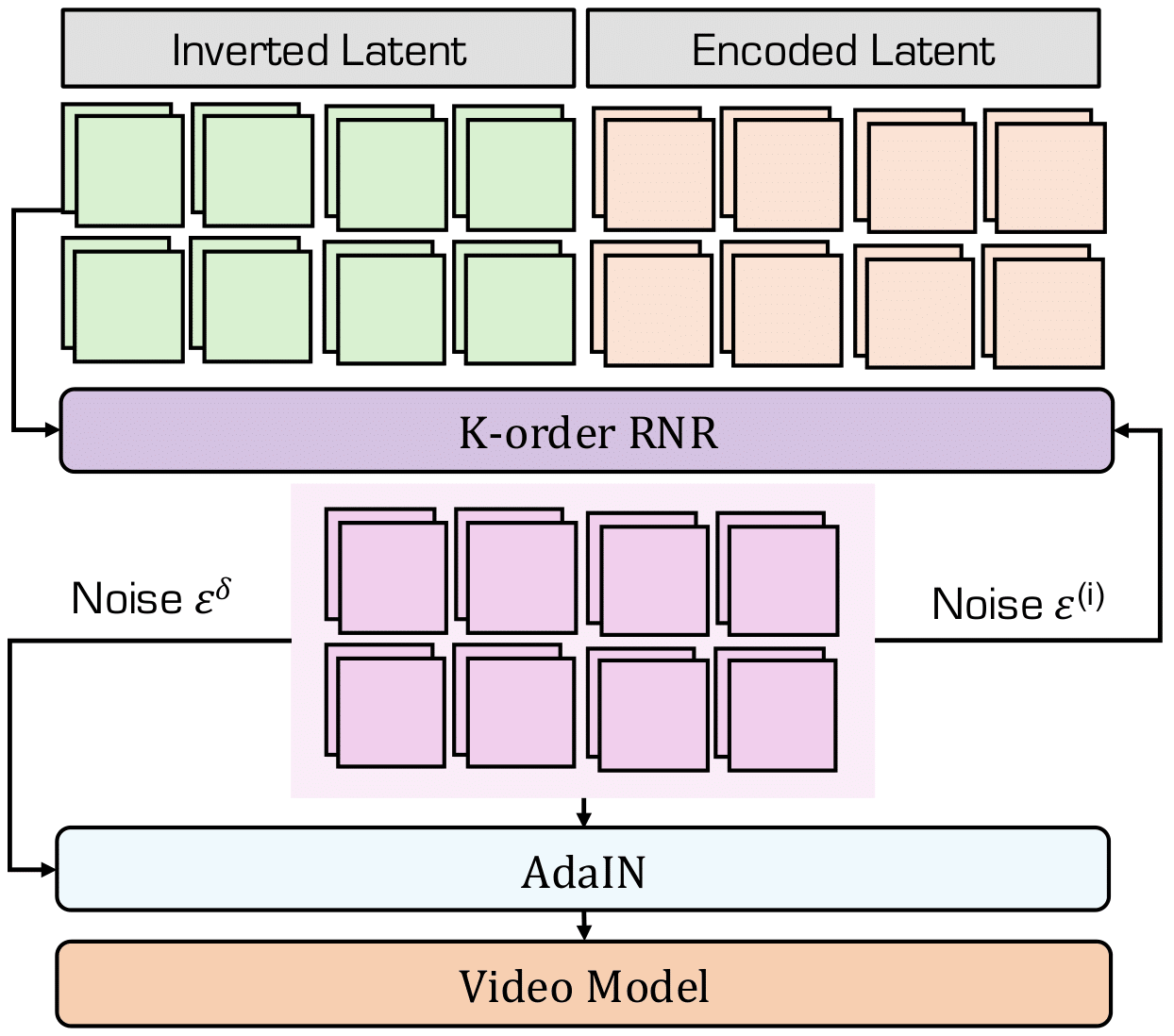
Given inverted latents from DDIM inversion and encoded latents from the VAE, our K-order Recursive Noise Representation (K-RNR) generates structured noise that aligns the two spaces. Adaptive Instance Normalization (AdaIN) modulates the resulting noise using an intermediate recursive state, and the final noise is fed into a pre-trained video diffusion model to generate novel views.
Qualitative Results
Comprehensive showcase of our method's performance across diverse scenarios and challenging cases. All experiments are conducted with CogVideoX-5B I2V architecture.
AI Generated Videos
Experiments demonstrating the identity and motion preservation capabilities of our method in Sora generated synthetic videos.
A corgi sits on a blue beach towel, holding a selfie stick with a GoPro
A corgi sits on a blue beach towel, holding a selfie stick with a GoPro
Cat wearing thick round glasses sits on a crimson velvet armchair
Cat wearing thick round glasses sits on a crimson velvet armchair
Van Gogh sits at a grand wooden desk
Van Gogh sits at a grand wooden desk
A monkey wearing red cap and a puffy blue vest sits atop a bench
A monkey wearing red cap and a puffy blue vest sits atop a bench
A confident corgi walks along the shoreline
A confident corgi walks along the shoreline
Recapturing Movie Scenes
Experiments investigating the effectiveness of our method in real world scenarios, specifically in the context of movie scenes. Creating a dynamic view in movie scenes requires preserving the identity and complex mouth, hand, and body motions.
A masked figure in suit stands against the of a modern cityscape
Two men are engaged in a serious conversation in front of an ornate building
A police officer in uniform, accompanied by two men in mid-20th century overcoats and hats
Two men in mid-20th century formal attire, including overcoats and fedoras, are on a boat
A cluttered mid-sized corporate office filled with standard office furnishings and supplies
Two hobbits dressed in worn cloaks sit among rugged, rocky terrain under a muted, overcast light
OpenVid-1M Examples
Experiments focusing on the human faces and body motions. OpenVid-1M is a large-scale dataset of humans performing various actions. Creating a dynamic view in OpenVid-1M requires preserving the identity and complex mouth, hand, and body motions.
A middle-aged man with graying hair, dressed in a dark coat and a purple shirt
A man in a beige suit and green shirt is seated at a table, engaging in a serious conversation
A middle-aged man with glasses, dressed in a light pink shirt, is seen standing indoors, possibly in a living room
A cluttered mid-sized corporate office filled with standard office furnishings and supplies
A man with short, dark hair, wearing a black turtleneck sweater, is seated in the driver's seat of a car
A woman with long, straight blonde hair and bangs is seated in a dark green booth, wearing a black top
Qualitative Comparisons
Side-by-side comparisons of our method with state-of-the-art approaches across diverse scenarios.
Original Video
Reference Video
3D Point Cloud Rendering
Render Video
Generative Camera Dolly
Stable Video Diffusion
TrajectoryAttention
Stable Video Diffusion
Diffusion as Shader
CogVideoX
TrajectoryCrafter
CogVideoX
ReCamMaster
Wan2.1
Ours [K=3]
CogVideoX
Ours [K=6]
CogVideoX
Original Video
Reference Video
3D Point Cloud Rendering
Render Video
Generative Camera Dolly
Stable Video Diffusion
TrajectoryAttention
Stable Video Diffusion
Diffusion as Shader
CogVideoX
TrajectoryCrafter
CogVideoX
ReCamMaster
Wan2.1
Ours [K=3]
CogVideoX
Ours [K=6]
CogVideoX
Original Video
Reference Video
3D Point Cloud Rendering
Render Video
Generative Camera Dolly
Stable Video Diffusion
TrajectoryAttention
Stable Video Diffusion
Diffusion as Shader
CogVideoX
TrajectoryCrafter
CogVideoX
ReCamMaster
Wan2.1
Ours [K=2]
CogVideoX
Ours [K=3]
CogVideoX
Original Video
Reference Video
3D Point Cloud Rendering
Render Video
Generative Camera Dolly
Stable Video Diffusion
TrajectoryAttention
Stable Video Diffusion
Diffusion as Shader
CogVideoX
TrajectoryCrafter
CogVideoX
ReCamMaster
Wan2.1
Ours [K=2]
CogVideoX
Ours [K=3]
CogVideoX
Original Video
Reference Video
3D Point Cloud Rendering
Render Video
Generative Camera Dolly
Stable Video Diffusion
TrajectoryAttention
Stable Video Diffusion
Diffusion as Shader
CogVideoX
TrajectoryCrafter
CogVideoX
ReCamMaster
Wan2.1
Ours [K=2]
CogVideoX
Ours [K=6]
CogVideoX